(SQL 첫걸음) 데이터 베이스 #5
데이터의 추가 , 삭제, 갱신
행 추가하기 - INSERT
Syntax INSERT 명령
INSERT INTO 테이블명 VALUES(값 1, 값 2, ···)
[예제]
SELECT * FROM SAMPLE41;
desc sample41;
insert into sample41 values(1,'ABC','2014-01-25') -- 데이터 추가
SELECT * FROM SAMPLE41;
값을 저장할 열 지정하기
Syntax 열을 지정해 행 추가하기
INSERT INTO 테이블명(열1, 열2, ... ) VALUES(값1, 값2, ...)[예제_열을 지정해 행 추가하기]
insert into sample41(a, no) values('XYZ', 2);
SELECT * FROM SAMPLE41;

NOT NULL 제약
insert into sample41(no, a, b) values(null, null, null);
위의 오류메시지를 발생시킴 왜냐?

NO는 NULL값을 허용하지 않는 NOT NULL 제약이 걸려있음.
NOT NULL 제약이 걸려있는 열은 NULL 값을 허용하지 않는다.
아래와 같이 변경해보고 실행해보자.
insert into sample41(no, a, b) values(3, null, null);
SELECT * FROM SAMPLE41;위 코드는 NOT NULL 제약조건을 위배하지 않아서 정상적으로 no에 3이 들어간 결과가 나타난다.

DEFAULT
DESC 명령으로 열 구성을 살펴보면 Default라는 항목을 찾을 수 있다. 명시적으로 값을 지정하지 않았을 경우 사용하는 초기값을 말한다. Default값을 테이블을 정의할때 지정할 수 있습니다.
DESC sample411;
[예제_명시적으로 디폴트 지정]
INSERT INTO sample411(no, d) VALUES(2, DEFAULT);
SELECT * FROM sample411;
0이 Default값으로 INSERT된 것을 확인할 수 있다.
→ 자주 사용하지 않는 방법이다.
[예제_암묵적으로 디폴트 지정]
INSERT INTO sample411(no) VALUES(3);
SELECT * FROM sample411;
no 3에 위와같이 명시하지 않았는데도 Default가 0으로 들어간것을 확인할 수 있다.
삭제하기 - DELETE
DELETE로 행 삭제하기
Syntax DELETE 명령
DELETE FROM 테이블명 WHERE 조건식[예제_sample41 테이블에 저장된 데이터를 확인]
SELECT * FROM sample41;
[예제_sample41에서 행 삭제하기]
sample41 테이블에서 no 열이 3인 행 삭제하기
<삭제하려고 하는데 발생하는 에러현상 해결하기>
Mysql에서 특정한 sql을 실행을 하는데, 아래와 같은 에러가 발생한다.
Error Code: 1175. You are using safe update mode and you tried to update a table without a WHERE that uses a KEY column To disable safe mode, toggle the option in Preferences -> SQL Editor and reconnect.
[방법 1]
set sql_safe_updates=0;
[방법 2]
Edit - Preference

Safe updates를 체크 해제하고 OK 누르고 workbench를 껏다가 다시 켜서 사용하자.

위 과정을 진행하면 이제 delete문을 실행해도 오류가 발생하지 않을 것이다.
DELETE FROM sample41 WHERE no = 3;
데이터 갱신하기
Syntax UPDATE 명령
UPDATE 테이블명 SET 열1 = 값1, 열2 = 값2, ...
WHERE 조건식UPDATE로 데이터 갱신하기
UPDATE 명령으로 행의 셀 값을 갱신 할 수 있다.
Syntax UPDATE 명령
UPDATE 테이블명 SET 열명 = 값 WHERE 조건식[원본 SAMPLE41]

UPDATE sample41 SET b = '2014-09-07' WHERE no = 2;
NULL값 대신 '2014-09-07'이 들어간걸 확인할 수 있음.
UPDATE로 갱신할 경우 주의사항
UPDATE sample41 set no = no + 1;
WHERE 구가 지정되어 있지 않으므로 갱신 대상은 테이블의 모든 행이 된다. SET 구에서는 no열의 값으 갱신하는데, 갱신 후의 값은 본래값(갱신 전의 값)에서 1을 더한 결과입니다.
복수열 갱신
UPDATE 명령의 SET 구에서는 필요에 따라 콤마(,)로 구분하여 갱신할 열을 여러개 지정할 수 있습니다.
Syntax UPDATE 명령
UPDATE 테이블명 SET 열명1 = 값1, 열명2 = 값2 ...
WHERE 조건식[예제_복수열 갱신]
UPDATE sample41 set b = '2023-03-15', a = 'DEF' where no = 2;
SELECT * FROM sample41;
no 2에 b는 2023-03-15, a는 'DEF'로 갱신완료된 모습
물리삭제와 논리삭제
물리삭제 -> DELETE로 삭제하는 것
논리삭제 -> 실제로 삭제가된 것은 아닌데 사용자에게 삭제된것 처럼 보이게 하는 삭제(UPDATE명령을 이용)
논리삭제의 장점 : 데이터를 삭제하지 않기 때문에 삭제되기 전의 상태로 간단히 되돌릴 수 있다는 것을 꼽을 수 있다.
아래와 같이 홈쇼핑이나 SNS 서비스 같은 곳에 개인정보를 다루는 시스템에서 사용하기 좋다.

물리삭제와 논리삭제는 용도에 맞게 선택해서 사용하자.
행 개수 구하기 - COUNT
COUNT(집합)
SUM(집합)
AVG(집합)
MIN(집합)
MAX(집합)
COUNT로 행 개수 구하기
Syntax COUNT
COUNT(집합)
select * from sample51;
select count(*) from sample51;
실행순서
-- 실행 순서
SELECT COUNT(*) -- 3
FROM SAMPLE51 -- 1
WHERE name='A' -- 2
;
A의 개수를 카운트
집계함수와 NULL값

' * (asterisk) ' : 모든 열에 대한 건수를 집계하고 건수가 가장 많은 것을 출력해줌(NULL 포함해서 COUNT)
SELECT COUNT(*),
COUNT(no),
COUNT(name),
COUNT(quantity)
FROM SAMPLE51
;
집계함수는 집합 안에 NULL값이 있을 경우 무시한다.
DISTINCT로 중복 제거
중복된 값을 제거하는 DISTINCT
(제거한다고해서 데이터값이 삭제되는 것은 아님, 보여줄때 하나만 보이게 해준다는 의미)
[예제] sample51 중복 제거하기

SELECT ALL name
FROM sample51;
SELECT distinct name
FROM sample51;
중복이 제거되어 표시된 모습
집계함수에서 DISTINCT
중복을 제거한 뒤 개수 구하는 예제
SELECT COUNT(ALL name), COUNT(distinct name)
FROM sample51;
COUNT(ALL | DISTINCT 값)에서 값을 생략할 경우 ALL이라 생략해도 OK.
COUNT 이외의 집계함수
Syntax SUM,AVG,MIN,MAX
SUM(ALL | DISTINCT | 집합)
AVG(ALL | DISTINCT | 집합)
MIN(ALL | DISTINCT | 집합)
MAX(ALL | DISTINCT | 집합)
SUM으로 합계 구하기
[원본 SAMPLE51]

SUM 집계함수를 사용해 집합의 합계를 구할 수 있다.
SELECT sum(quantity)
FROM SAMPLE51;
AVG으로 평균값 구하기
SELECT sum(quantity),
avg(quantity)
FROM SAMPLE51;
AVG 집계함수도 NULL값은 무시한다.
즉 NULL 값을 제거한 뒤에 평균값을 계산한다.
NULL값을 0으로 간주해서 계산하면 또 평균값이 바뀌니 주의해야함.
아래의 예제를 참고하자. CASE를 사용해도 되는데 너무 길어지므로 ifnull 사용하는것을 추천함.
SELECT sum(quantity),
avg(ifnull(quantity,0))
FROM SAMPLE51;
MIN · MAX로 최솟값 · 최댓값 구하기
MIN 집계함수, MAX 집계함수를 사용해 집합에서 최솟값과 최댓값을 구할 수 있다.
숫자뿐만 아니라 문자열형과 날짜 시간형에도 사용할 수 있다. NULL 값을 무시하는 기본규칙은 다른 집계함수와 같다.
[SAMPLE51]

[예제_MIN · MAX로 최솟값 · 최댓값 구하기]
SELECT sum(quantity),
avg(ifnull(quantity,0)),
MIN(quantity),
MIN(name)
FROM SAMPLE51;
그룹화 - GROUP BY
_Syntax_GROUP BY
SELECT * FROM 테이블명 GROUP BY 열1, 열2, ...
GROUP BY를 지정해 그룹화하면 DISTINCT와 같이 중복을 제거하는 효과가 있다.
GROUP BY로 그룹화
SELECT * FROM sample51;
SELECT name FROM sample51 GROUP BY name;

[예제_name열을 그룹화해 계산하기]
SELECT name, count(name), sum(quantity)
FROM sample51
GROUP BY name
;
HAVING 구로 조건 지정
[WHERE 구에서는 집계함수를 사용할 수 없음]

SELECT name, COUNT(name) FROM sample51
where COUNT(name) = 1 GROUP BY name;위와 같이 작성하고 실행시키면 오류가 발생한다.
[내부 처리 순서]
where - group by - select - order by
집계함수를 사용할 경우 HAVING 구로 검색조건을 지정
[예제_HAVING을 사용해 검색하기]
SELECT name, count(name), sum(quantity)
FROM sample51
GROUP BY name
having count(name) = 1
;복수열의 그룹화
GROUP BY를 사용할 떄 주의할점
GROUP BY에 지정 한 열 이외의 열은 집계함수를 사용하지 않은 채 SELECT 구에 기술해서는 안된다.
아래 그림에서 group by name으로 name열을 그룹화 했다. 이 경우 select 구에 name을 지정하는 것은 문제없지만 , no 열이나 quantity 열을 select구에 그대로 지정하면 데이터베이스 제품에 따라 에러가 발생한다.

아래 그림 A의 quantity에 값을 처리할때 어느 값을 출력해야하는지 모르게 됨. 집계함수를 사용해 하나의 값으로 계산 해주어야한다.

select min(no), name, sum(quantity)
from sample51
group by name
;
GROUP BY에서 지정한 열 이외의 열은 집계함수를 사용하지 않은 채 SELECT 구를 지정할 수 없다.
결과값 정렬
GROUP BY로 그룹화해도 실행결과 순서를 정렬할 수 없다. 이럴 때는 ORDER BY를 사용해 결과를 정렬할 수 있다.
[예제_집계한 결과 정렬하기]
[원본 sample51]

name 열로 그룹화해 합계를 구하고 내림차순으로 정렬
SELECT name, COUNT(name), SUM(quantity)
FROM sample51 GROUP BY name ORDER BY SUM(quantity) DESC;
서브쿼리(sub query)
쿼리안에 또 다른 쿼리 작성
Syntax 서브쿼리
(SELECT 명령)
DELETE의 WHERE 구에서 서브쿼리 사용하기
SELECT * FROM sample54;
최솟값 검색하기
SELECT MIN(a) FROM sample54;
[예제_최솟값을 가지는 행 삭제하기]
delete from sample54 where a = (select min(a) from sample54);
DELETE FROM sample54 WHERE a = (SELECT a FROM (SELECT MIN(A) AS a FROM sample54) AS x);-- MYSQL에서는 위 첫번째 코드는 오류가 발생한다. 아래의 코드를 사용해서 실행
'delete from sample54 where a = (select min(a) from sample54) Error Code: 1093. You can't specify target table 'sample54' for update in FROM clause'위의 코드로 작성햇다면 오류가 발생한다.
MYSQL에서는 데이터를 추가하거나 갱신할 경우 동일한 테이블을 서브쿼리에서 사용할 수 없도록 되어있기 때문이다.

괄호로 서브쿼리를 지정해 삭제한 모습이다.
스칼라 값
- 스칼라
SELECT (SELECT * FROM 테이블명)
FROM 테이블명 - 서브쿼리
SELECT
FROM 테이블명
WHERE 열명 = (SELECT FROM 테이블명)
2-1. 단일행 서브쿼리 : 소괄호 안의 select의 결과가 하나인 경우
2-2. 다중행 서브쿼리 : IN 소괄호 안의 select의 결과가 두개(줄) 이상인 경우
3. 인라인뷰(as키워드를 이용하여 가상의 테이블명 반드시!! 꼭!! 선언해야 함.)
SELECT
FROM (SELECT FROM 테이블명) AS 가상테이블명
[예제 서브쿼리의 패턴]
1(스칼라값). 하나의 값을 반환하는 패턴
SELECT MIN(a) FROM sample54;

2.복수의 행이 반환되지만 열은 하나인 패턴
SELECT no FROM sample54;

- 하나의 행이 반환되지만 열이 복수인 패턴
SELECT MIN(a), MAX(no) FROM sample54;
- 복수의 행, 복수의 열이 반환 되는 패턴
SELECT no, a FROM sample54;
한 행의 한 칸으로 된것을 스칼라라고 함.
SELECT COUNT(*) FROM sample51;
SELECT COUNT(*) FROM sample54;

[예제_SELECT 구에서 서브쿼리 사용하기]
SELECT
(SELECT COUNT(*) FROM sample51) AS sq1,
(SELECT COUNT(*) FROM sample54) AS sq2
;
[예제_SELECT 구에서 서브쿼리 사용하기(Oracle의 경우)]
SELECT
(SELECT COUNT(*) FROM sample51) AS sq1,
(SELECT COUNT(*) FROM sample54) AS sq2 FROM DUAL
;
SET 구에서 서브쿼리 사용하기
update 테이블명
set 변경하고자 하는 열 = (select * from 테이블명)
where 조건식
[예제]
-- sample54 테이블의 a열 전체에 900으로 변경
update sample54
set a = 900
;
-- sample54테이블의 a열 전체에 sample54테이블의 a열의 최대값으로 변경
update sample54
set a = (select a from (select max(a) from sample54)as x)
;
-- sample54 테이블에서 a열의 값이 가장 큰 수
select max(a) from sample54;
FROM구에서 서브쿼리 사용하기
[예제_FROM 구에서 서브쿼리 사용하기][예제 FROM 구에서 서브쿼리 사용하기(AS로 지정)]
-- 인라인뷰
SELECT * FROM (SELECT * FROM sample54) sq;
SELECT * FROM (SELECT * FROM sample54) AS sq; -- AS 별칭 설정하는건 생략해서 사용해도 됨.- 실제 업무에서 FROM 구에 서브쿼리를 지정하여 사용하는 경우[페이징할때 사용됨]
SELECT @rownum:=0;
SELECT @rownum:=@rownum + 1 rownum, no, a -- ② @rownum + 1 : 1씩 증가시킴
FROM SAMPLE54,
(SELECT @rownum:=0) TMP -- ① 0으로 세팅된 상태로 시작해서
;
INSERT 명령과 서브쿼리
INSERT 명령과 서브쿼리를 조합해 사용할 수 도 있습니다. INSERT 명령에는 VALUES구의 일부로 서브쿼리를 사용하는 경우와, VALUES구 대신 SELECT 명령을 사용하는 두 가지 방법이 있습니다.
value구에서 서브쿼리 사용하기
이때 서브쿼리는 스칼라 서브쿼리로 지정할 필요가 있습니다. 물론 자료형도 일치해야한다.
[예제_value구에서 서브쿼리 사용하기]
INSERT INTO SAMPLE541 VALUE(
(SELECT COUNT(*) FROM SAMPLE51),
(SELECT COUNT(*) FROM SAMPLE54)
);
[INSERT SELECT]
VALUES 구 대신에 SELECT 명령을 사용하는 예를 살펴보겠습니다.
[예제_SELECT 결과를 INSERT하기]
INSERT INTO sample541 SELECT 1, 2;
SELECT * FROM sample541;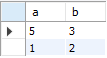
흔히 'INSERT SELECT'라 불리는 명령으로 INSERT와 SELECT를 합친 것 같은 명령이 되었습니다. SELECT가 결과값으로 1과 2라는 상수를 반환하므로, INSERT INTO sample541 VALUES(1,2)의 경우와 같습니다.
이때 SELECT 명령이 반환하는 값이 꼭 스칼라 값일 필요는 없다.
INSERT SELECT 명령은 SELECT 명령의 결과를 INSERT INTO로 지정한 테이블에 전부 추가합니다.
SELECT 명령의 실행 결과를 클라이언트로 반호나하지 않고 지정된 테이블에 추가하는 것입니다. 이 때문에 데이터의 복사나 이동을 할 때 자주 사용하는 명령입니다.
열 구성이 똑같은 테이블 사이에는 다음과 같은 INSERT SELECT 명령으로 행을 복사할 수도 있다.
[예제_테이블의 행 복사하기]
INSERT INTO sample542 SELECT * FROM sample543;